Next: 6 Example: SAR System Application Up: Appnotes Index Previous:4 Performance Modeling Environments
![]()
![]()
![]()
![]()
Next: 6 Example: SAR System Application
Up: Appnotes Index
Previous:4 Performance Modeling Environments
In ATL's RASSP concept, co-design begins immediately after the requirements for the signal processing subsystem have been established and continues throughout the remainder of the process. It begins with trade-offs in the initial decisions and occurs at an abstract level. The co-design continues with joint trade-offs occurring down to the very detailed levels of hardware and software, where applicable.
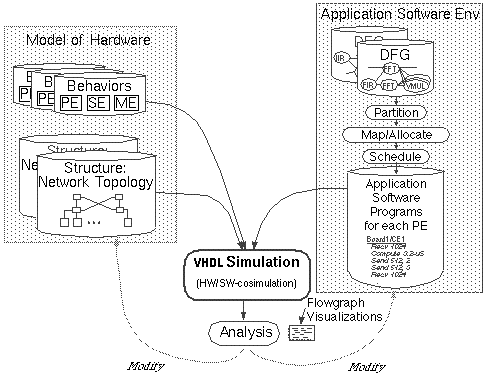
Figure 5 - 1 below illustrates the co-design concept as applied to Lockheed Martin ATL's performance modeling environment. The shaded block on the left indicates the description of the candidate hardware system, while the shaded block on the right indicates the description of the system's application software. The hardware is described as the topological interconnection of the building-block element models. The software is described at several levels beginning with the data-flow-graph (DFG) of the application and resolved to sequences of abstract software tasks for each target processor element. The target software programs are the result of a partitioning, mapping, and scheduling process. The proposed hardware and software design are brought together during simulation. The system is simulated as the software executing on the hardware. The abstract target software programs are interpreted by the abstract hardware models. The results of simulation consist of time-lines and utilization statistics that are then analyzed for improvements to the hardware, the software, or combinations of both.
The following sections summarize the steps to be used for conducting performance modeling. This discussion is particularly appropriate to the ATL performance model library. However, similar methods apply for the Adept, Cosmos, or other modeling environments. The outlined methods can be adapted accordingly..
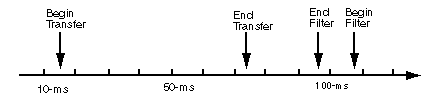
Resolved events should be on the order of thousands of clock-cycles. For example, the begin and end events could be resolved for a data transfer as shown in figure 5 - 2, or for a PE computing a vector arithmetic operation, such as Fast-Fourier-Transform (FFT), as opposed to a single clock-cycle scalar operation.
Contention for memory, communication, and computation resources should be resolved to accurately account for competing interactions. This can be done by allocating specific resources for the period of use and blocking competing operations while needed resources are not available.
Major system events of interest should be modeled for visibility into the processing. For instance, the transition between major sections of an algorithm can be identified.
In general, smaller sequential events whose time-delay and sequence can be accurately predicted should be aggregated into a single pair of begin-end events representing the start and conclusion of the group. The largest groups, for which accurate time delays can be predicted, should be formed. For example, the uni-processor tasks between inter-PE communication events of a partitioned algorithm can usually be aggregated.
Inter-device communication events should be resolved to account for network traffic. Communications should be resolved only down to the packet or message level as opposed to word transfer level. For instance, only the beginning and ending of a packet transfer need be resolved, assuming that the time for the packet transfer to complete (once started) is determined by the packet length, the transfer rate, and a fixed overhead.
Processor Element
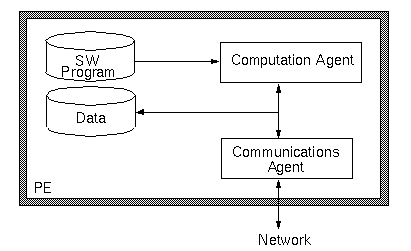
The PE for a Multiple-Instruction-Multiple- Data (MIMD) system is conceptually divided into two concurrent processes: the computation agent, and the communications agent. The PE contains local memory for storage of the software program and working data as shown in figure 5 - 3. The performance model of the PE does not store any actual data. Rather, it keeps track of how much data would be stored in various logical queues by the application algorithm.
The communications agent handles the reliable transfer of data between the other PEs and the local PE's memory queues. It implements whatever link layer protocols, packetization, and retry or blocked message resumption that are needed to transfer and receive arbitrary length data messages over the network. Upon reception of data, the communications agent increments the data amount of the destination queue by the received amount. If the computation agent was blocked waiting for the received data, the communications agent would allow the computation agent to resume. Likewise, upon sending data, the communications agent decrements the data amount of the local source queue
by the transmitted amount.
The computation agent represents the hardware side of the interface between the hardware and software because it interprets the software application program instructions into specific hardware actions. The computation agent executes a partitioned flow graph. A simple example of a computation agent for a statically scheduled, single-thread-per-PE
system is described here. Extensions to other cases can be made as appropriate. Within the scope of the network performance level, the abstract instruction set of the computation agent may consist of four basic instructions: compute, send, receive, and loop. Although these instructions are abstract, their interpretation by the PE performance model is
perfectly analogous to assembly code execution by an ISA model. The computation agent maintains a program counter to keep track of the software application program instruction it is executing.
The compute instruction represents the execution of a portion of the application algorithm within the PE's local memory. It is modeled in the performance model as a simple time delay. The compute instruction contains one operand specifying an algorithm step or corresponding computation time. The length of the time delay is equal to the time
required for the target PE to perform the respective algorithm step. The time-delay value depends both on the type of PE and on the operations contained in that step of the algorithm. The time values can be obtained a variety of ways depending on the case. For COTS PEs, reliable time measurements for common processing functions, such as FFT, or
vector multiply can often be obtained from data books and other published sources. Benchmark measurements of actual or typical algorithm segments can also be taken from an ISA simulation model or physical PE for a COTS processor when reliable measurements for the required operations cannot otherwise be obtained. For custom PE's that have not
been constructed, either quick estimates based on intrinsic operation counts and the projected PE operation rate can be made or benchmarks can be taken from ISA simulation models. Upon completion of a computation delay interval, the computation agent interprets the next sequential instruction in the software application program. Because this is a
performance model, no application computations are actually performed in the model.
The send instruction represents an inter-PE data transfer. It contains three operands: the local and destination queue numbers, and the data amount. Other operands, such as priority may be modeled. When the computation agent encounters a send instruction, the computation agent directs the local communication agent to transfer data from a local memory queue to a queue in another PE. If the communication agent can accept the command immediately, the computation agent continues sequencing to the next instruction in the software application program. Otherwise, the computation agent blocks execution until the communication agent resumes. Many systems feature a command queue for the communication agent that can be modeled to minimize such blocking. No data is actually transferred in a performance model. The model describes only the effects of transferring data, such as port allocation for the amount of time required to send the specified data amount and memory allocation amount for storing the equivalent data.
The receive instruction represents the consumption of transferred data. It has two operands: queue number and data amount. If the sufficient amount of data had arrived in the specified queue prior to encountering a receive command, then the computation agent decrements the specified queue by the specified receive amount. Then it continues to sequence to the next instruction in the software application program. Otherwise, the computation agent blocks until sufficient data in the specified queue arrives.
Switch Element (SE)
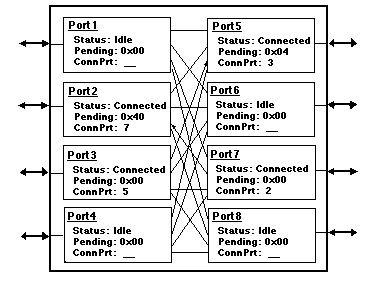
The SEs are multiple port entities that route data packets or messages from one port to another port. When connected to other SEs via links to form a network, the SEs provide a means to transfer data from one PE to any other PE or ME within the processing system. For a network-performance model, no data is actually transferred over the links. However, a link's bandwidth is allocated for the appropriate duration of a data transfer to account for the movement of data over the given link. Various switching schemes may be modeled, such as common-bus, circuit-switched, packet-switched, or store-and-forward. Each scheme exhibits unique behavior under contention for common network links by competing PE nodes. The effects of such contentions are especially critical to the successful design of real-time, high-throughput, signal processors for many applications. An SE can be modeled as a set of processes handling the activity at each of the ports, as shown in figure 5 - 4.
Shared Memory Element (ME)
The shared ME represents a common data storage resource accessible by PEs over the network. Its model and role are similar to that of the local memory of a PE.
Modeling Issues and Techniques
The PMS paradigm described above can be implemented with VHDL in various ways. We advocate a direct approach where the network topology is described directly in terms of a VHDL structural description. Because the physical structure of digital systems typically consists of a hierarchy of modules, boards, chassis, and racks, we pattern the structural hierarchy after the physical hierarchy. The PEs, SEs, and MEs become the leaf-level components of the structural description. The signal links of the structural models interconnect the leaf-level components to each other.
Because the abstract network-level paradigm transfers only symbolic tokens representing data messages instead of actual data values, a token composite type must be defined. The signals and component ports are declared to be of type token.
The use of a common token definition is critical for the re-use and interoperability of abstract models from diverse sources such as libraries and other project groups. Honeywell Technology Center has proposed a token type convention for performance modeling [10], as shown below.
The behaviors of the network components (PE, ME and SE) are modeled in procedural VHDL in accordance with the paradigm described in section 5.1, 5.3.1 and 5.3.2. Because the duration of modeled events in on the order of thousands of clock cycles, the models should be asynchronous, event-driven models, as opposed to synchronous clock-driven models. This minimizes the number of events to be executed by the VHDL simulator and avoids the inefficiency of evaluating many clock events for which no meaningful system event occurs.
For a given network architecture, the application flow graph is partitioned for allocation to PEs in the system. The partitioned flow graph nodes may be allocated statically at design-time or dynamically at run-time. In either case, the tasks may be scheduled for execution statically or dynamically. The subject of partitioning/mapping/scheduling remains an open research topic that is beyond the scope of this discussion [11,12,13]. However, the paradigm described here allows either of the cases to be modeled. Dynamic allocation and scheduling requires modeling the dynamic mapper and scheduler. Static allocation and scheduling requires the mapping and scheduling to be done prior to simulation. The regularity of many DSP applications allows static scheduling, as described in this paper.
The static partitioning/mapping/scheduling process produces a set of pseudo-code software application programs for each of the PEs. The scheduling determines only the order of tasks executed by a given PE. The actual time when execution begins for each task is determined by the task sequence and the inherent data flow control of the send/receive
paradigm. The PE programs are expressed as a sequence of pseudo-code instructions from the simple instruction set described in section 5.3.1 under Processor Element. New mappings and schedules can be tested by rearranging the instructions accordingly.
Once simulations show a suitable software mapping and hardware architecture combination to satisfy the system performance requirements, the pseudo-code software routines are expanded into high-level-language subroutine calls, which are compiled for down-loading to the target hardware or more detailed ISA models for verification of the constituent performance factors. The send/receive calls are substituted with the appropriate communication routines for the target system. The compute instructions are substituted by calls to the appropriate DSP library routines or functions.
Examples of model aspects that can be incrementally refined include the network loading behavior and the task primitive execution times which may have been initially based on estimates.
For instance, accurate timing values can be obtained from an application code segment running on an Instruction Set Architecture (ISA) model of a target processor element (PE). The new values update the task execution time lookup-table for the given PE type. For example, on the RASSP Benchmark - II Synthetic Aperture Radar (SAR) design project [14], the values of the performance model's task execution time table were updated with measurements from a physical development system.
Initially, the SAR task partitioning was determined and validated by performance simulations based on estimates from a summation of the published execution times of the individual vector functions that comprised the various application tasks. Then each of the aggregate tasks was executed on a single target PE that was available on a development board. The actual execution times were compared against the estimates to check for consistency and then the actual time values were used in re-simulating the full system running the complete application to assure that the appropriate design margins were retained or to re-partition if needed.
Another instance of model refinement from the SAR design project involved the resolution of network protocol. The initial models resolved the transfer of data between PE's down only to the message level. However, intercommunication benchmarks showed that under moderate to heavy traffic loads the performance predicted by the modeled system deviated substantially from that observed on a small physical development system. The inconsistency was traced to the effects of contention and the packetization of messages into finite length packets on the target system. It was found that by resolving the message packetization process, the model's behavior was brought into consistency with the observed performance. The model was validated as a result of this process.
5.0 Performance Modeling Method
5.1 Descriptive paradigm
The Processor-Memory-Switch (PMS) paradigm [9] describes the hardware architecture of a processing system as the structural interconnection of PEs, network switch elements (SEs), and shared memory elements (MEs). The interconnecting links are considered as monolithic data conduits that may represent, for example, fiber, coax, twisted pair, or bundles of conductors. The links are characterized by their data transfer rate, fixed transfer latency, and protocol relative to its performance as a function of demanded load. The PEs, SEs, and MEs are described behaviorally, and therefore possess no further decomposition of internal structure as is consistent with network performance modeling.
5.2 HW/SW-Codesign process
The hardware/software co-design process is characterized by making design decisions and trade-offs between hardware and software in a cooperative and iterative fashion. This concept is in contrast to traditional approaches where the hardware architecture is selected and set prior to designing the software, or vice versa. Approaches without co-design preclude potentially superior solutions because decisions are made in the absence of total design information.
5.3 Steps for Token-Based Performance Modeling
The following sections summarize the steps to be used for conducting performance modeling. This discussion is particularly appropriate to the ATL performance model library. However, similar methods apply for the Adept, Cosmos, or other modeling environments. The outlined methods can be adapted accordingly. 5.3.1 Hardware Description
The following are guidelines for selecting the appropriate model abstraction level for network modeling. These are especially useful for multiple-instruction, multiple-data (MIMD) architectures with large granularity mappings.
TYPE utoken IS
RECORD
destination : name_type;
source : name_type;
t_type : token_type;
size : data_size;
value : INTEGER;
id : uGIDType;
start_time : TIME;
priority : INTEGER;
state : State_type;
protocol : Protocol_Type;
collisions : INTEGER;
retries : INTEGER;
route : INTEGER;
param_int : INTEGER;
END_RECORD
5.3.2 Software Description
In the ATL approach, the signal processing application algorithm is first represented as a data flow graph (DFG). The DFG is a directed graph that describes an application algorithm in terms of the inherent data dependencies of its mathematical operations. The graph nodes represent mathematical operations, and the arcs that interconnect the nodes
represent the data dependencies and form the logical data queues. The DFG conveys the potential concurrencies within an algorithm, which facilitates parallelization and mapping to arbitrary architectures. The DFG nodes usually correspond to DSP primitives, such as FFT, vector multiply, convolve, or correlate.
5.3.3 Simulation
At the start of simulation, the hardware models read their respective application software programs and begin to interpret them. The interpretation of the software programs causes the processor elements to send and receive messages over the network, and to delay for specific computation events. The designer can set break-points for specific times to
examine the simulated system's status. VHDL simulators provide extensive capabilities for viewing the values of each model's internal states. This is very helpful while debugging. During simulation, event-history information is recorded into files for post-processing analysis.
5.3.4 Postprocessing/Analysis
To visualize the result of a simulation, the event-history file can be translated into an xy-graph format for plotting the
time-line information. A useful event format is as follows:
device @ time: event-string
Where device is the name of the entity on which the event occurred.
Time is the time at which the event occurred. and the event-string
is a meaningful description or name of the event. For example:
/board1/PE_03 @ 1923.084: Began FFT_1024
/board4/xbar7 @ 1925.921: Transferred packet
5.3.5 Recursion
To determine the sensitivity of a design parameter, it is often useful to execute a simulation iteratively: each time changing the parameter slightly. It is usually convenient to set up the simulation recursion information in a script file so that the recursions are run automatically. The information can be collected and displayed automatically as well.
5.3.6 Model Validation/Maintenance
As the design process progresses, a performance model's accuracy should be continually checked against more detailed models as they become available or to measurements from the actual components. Any mismatch should be corrected to maintain the performance model's accuracy, to test for continued compliance with requirements, and to support subsequent re-use and model-year upgrades. This activity departs from traditional processes which do not maintain -and therefore effectively discard- the performance model once the architecture design has completed.
![]()
![]()
![]()
![]()
Next: 6 Example: SAR System Application
Up: Appnotes Index
Previous:4 Performance Modeling Environments